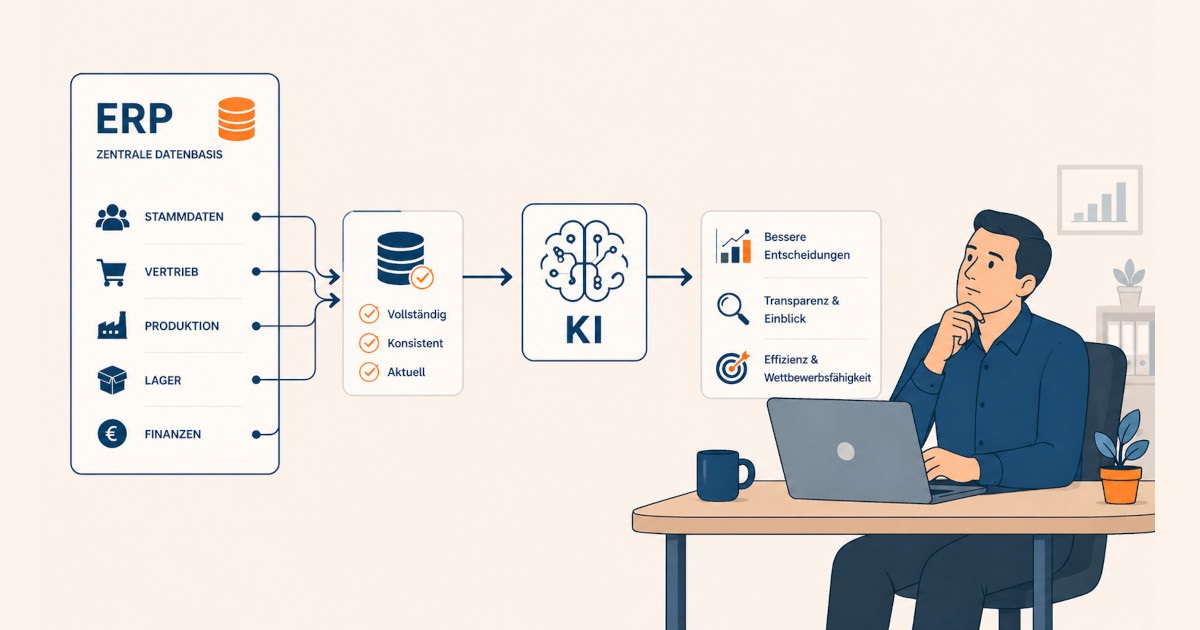
In vielen Unternehmen ist die Diskussion über künstliche Intelligenz längst im Alltag angekommen. Es geht um Assistenten, Prognosen, automatische Auswertungen, Copilots, Wissenszugriff oder Prozessunterstützung. Gleichzeitig arbeiten viele Unternehmen operativ noch mit einer Landschaft aus ERP, Einzellösungen, Excel-Dateien, Sonderlogiken und manuell gepflegten Zwischenständen. Genau an dieser Stelle beginnt das eigentliche Problem. Nicht die Frage, welches KI-Werkzeug zuerst eingeführt wird, entscheidet über den Nutzen. Entscheidend ist, ob die zugrunde liegende Daten- und Prozessbasis überhaupt tragfähig ist.
Warum das Thema gerade jetzt relevant ist
Die eigentliche Dringlichkeit liegt nicht darin, dass KI plötzlich möglich geworden wäre. Dringlich ist, dass viele Unternehmen den Einstieg bereits planen oder erste Werkzeuge ausprobieren, während ihre Kerndaten fachlich noch nicht sauber geführt werden. Damit verschiebt sich die Reihenfolge. Statt erst die Datenbasis zu klären und dann KI darauf aufzusetzen, wird häufig versucht, Unordnung mit neuer Technologie zu überdecken.
Genau hier liegt die operative Gefahr. KI-Systeme können Inhalte verdichten, Muster erkennen, Antworten ableiten oder Vorschläge generieren. Aber sie brauchen dafür einen belastbaren fachlichen Untergrund. Wenn Kunden-, Artikel-, Preis-, Bestands-, Auftrags- oder Buchungsdaten uneinheitlich gepflegt werden, skaliert KI nicht Wissen, sondern Unsicherheit. Sie macht ein strukturelles Datenproblem nicht kleiner, sondern sichtbarer und im Zweifel wirkungsvoller.
KI scheitert selten zuerst am Modell, sondern an der operativen Wirklichkeit
Viele Unternehmen unterschätzen, wie stark KI-Anwendungen von operativen Grunddaten abhängen. In Strategiedecks klingt es oft so, als könne man erst mit Use Cases starten und die Datenbasis später nachziehen. In der Praxis funktioniert das nur sehr begrenzt.
Wenn ein Modell Umsätze, Bedarfe, Liefertermine, Servicefälle oder kaufmännische Zusammenhänge interpretieren soll, braucht es mehr als Datenmengen. Es braucht fachlich verwertbare Daten. Das bedeutet: Begriffe müssen gleich verwendet werden, Status müssen eindeutig sein, Dubletten dürfen nicht den Regelfall bilden, Schnittstellen dürfen keine unerklärten Abweichungen erzeugen, und zentrale Geschäftsobjekte müssen einem führenden Bezugssystem folgen.
Genau deshalb ist ERP in diesem Zusammenhang mehr als nur Verwaltungssoftware. Ein ERP ist dort strategisch relevant, wo ein Unternehmen festlegen muss, welche Daten für Aufträge, Beschaffung, Bestandsführung, Leistungserbringung, Rechnungsstellung und betriebswirtschaftliche Steuerung fachlich führend sind. Ohne diese Führungslogik bleibt jede spätere KI-Anwendung auf unsicherem Fundament.
Was eine saubere ERP-Datenbasis für KI tatsächlich bedeutet
Eine KI-taugliche ERP-Datenbasis bedeutet nicht, dass jedes einzelne Datum ausschließlich in einem einzigen System lebt. Diese Vorstellung ist in gewachsenen Unternehmensarchitekturen meist unrealistisch. Gemeint ist etwas anderes: Für zentrale fachliche Aussagen muss klar sein, welches System führend ist, welcher Prozesszustand gilt und wer für Qualität, Pflege und Änderungen verantwortlich ist.
Für die Praxis heißt das zum Beispiel:
- Ein Auftrag darf nicht in Vertrieb, ERP und Reporting unterschiedlich verstanden werden.
- Bestandszahlen dürfen nicht je nach Auswertung andere Realitäten zeigen.
- Preise, Artikelstammdaten und Kundeninformationen dürfen nicht gleichzeitig an mehreren Stellen ohne klare Führung gepflegt werden.
- Prozesszustände wie offen, freigegeben, geliefert, abgerechnet oder storniert müssen fachlich sauber definiert sein.
- Schnittstellen müssen so aufgebaut sein, dass Änderungen nachvollziehbar bleiben und Fehler nicht unbemerkt in Folgeprozesse laufen.
Für KI ist das deshalb entscheidend, weil Modelle fachliche Uneindeutigkeiten nicht automatisch auflösen. Sie können nur mit dem arbeiten, was ein Unternehmen an Struktur, Qualität und Prozessklarheit bereitstellt.
Fünf Bausteine für eine ERP-Datenbasis, auf der KI sinnvoll arbeiten kann
1. Führende Geschäftsobjekte und Verantwortlichkeiten festlegen
Der erste Schritt ist nicht technisch, sondern fachlich. Unternehmen müssen für ihre wichtigsten Geschäftsobjekte klar bestimmen, wo die führende Wahrheit liegt. Das betrifft typischerweise Kunden, Artikel, Aufträge, Bestellungen, Bestandsdaten, Rechnungen und Leistungsnachweise. Ebenso wichtig ist die Frage, wer diese Daten fachlich verantwortet und nach welchen Regeln sie geändert werden dürfen.
Ohne diese Klärung entsteht ein typischer KI-Fehler: Mehrere Datenquellen sehen plausibel aus, widersprechen sich aber im Detail. Dann ist nicht nur die Auswertung unsicher. Auch jede automatisierte Ableitung wird fragwürdig.
2. Prozesszustände fachlich sauber definieren
KI braucht nicht nur Datenfelder, sondern Kontext. Ein offener Auftrag ist nur dann sinnvoll interpretierbar, wenn klar ist, was offen fachlich bedeutet. Gilt das bereits nach Auftragseingang, erst nach Freigabe, nur ohne Lieferblockade oder nur ohne Faktura? Solche Fragen wirken banal, sind in der Praxis aber häufig unklar oder historisch gewachsen.
Wer Prozesszustände nicht sauber definiert, erzeugt Inkonsistenz an einer Stelle, die für KI besonders kritisch ist. Denn Modelle, Reports und Assistenten arbeiten immer mit Kategorien, Regeln und Bedeutungen. Sind diese Bedeutungen uneinheitlich, werden auch die Ergebnisse unzuverlässig.
3. Stammdatenqualität und Pflegeprozesse ernst nehmen
Viele KI-Initiativen scheitern bereits an Problemen, die nicht neu sind: Dubletten, uneinheitliche Benennungen, fehlende Pflichtfelder, veraltete Datensätze oder historisch gewachsene Freitextstrukturen. Solange diese Themen als lästige Nebenaufgabe behandelt werden, bleibt jede spätere KI-Nutzung anfällig.
Stammdatenqualität ist kein kosmetisches Projekt. Sie entscheidet darüber, ob Daten überhaupt aggregierbar, vergleichbar und auswertbar sind. Gerade im ERP-Umfeld braucht es deshalb klare Regeln für Anlage, Änderung, Freigabe, Versionierung und Bereinigung.
4. Integrationen so bauen, dass Datenbewegungen nachvollziehbar bleiben
Eine saubere ERP-Datenbasis endet nicht an der Systemgrenze. In nahezu jedem Unternehmen müssen CRM, Shop, Lager, Service, BI, Dokumentenprozesse oder Fachanwendungen mit dem ERP zusammenspielen. Genau dort entstehen oft die Fehler, die später fälschlich als KI-Problem gelesen werden: verzögerte Synchronisation, doppelte Schreibrechte, unsaubere Mapping-Logik oder fehlende Rückmeldung bei Fehlern.
Wer KI auf ERP-Daten aufsetzen will, muss deshalb auch die Integrationsarchitektur ernst nehmen. Relevant ist nicht nur, ob Daten technisch fließen, sondern ob Herkunft, Zeitpunkt, Freigabe und Geltungsbereich eindeutig nachvollziehbar bleiben.
5. Governance, Zugriff und Auditierbarkeit mitdenken
Sobald Datenbasis und KI in denselben Entscheidungsraum rutschen, wird Governance zur Pflicht. Es muss klar sein, wer Datenstrukturen ändern darf, wer Schnittstellen freigibt, wer auf sensible operative Daten zugreifen kann und wie fachliche Änderungen dokumentiert werden. Ebenso wichtig ist, welche KI-Anwendungen überhaupt auf welche Daten zugreifen dürfen und wo bewusste Grenzen bleiben.
Nicht jede Organisation braucht dafür sofort ein großes Governance-Programm. Aber jede Organisation braucht ein Mindestmaß an Daten- und Architekturdisziplin. Ohne diese Basis wird KI später nicht nur technisch, sondern auch organisatorisch schwer steuerbar.
Warum typische Abkürzungen nicht tragen
Ein häufiger Einwand lautet, dass erste KI-Tests auch auf unvollkommener Datenbasis möglich seien. Das stimmt eingeschränkt. Für Experimente, Ideenskizzen oder isolierte Assistenzfunktionen kann das ausreichen. Problematisch wird es dort, wo aus Tests operative Erwartungen werden. Spätestens wenn Ergebnisse Entscheidungen beeinflussen, Prozesse anstoßen oder Managementaussagen stützen sollen, reicht ungefähr richtig nicht mehr.
Ein zweiter Einwand lautet, dass ERP für dieses Thema zu groß gedacht sei. Auch das greift zu kurz. Die Frage ist nicht, ob sofort ein neues ERP eingeführt werden muss. Die Frage ist, ob das Unternehmen für seine zentralen Geschäftsobjekte, Prozesszustände und Datenverantwortungen bereits ein tragfähiges Führungsmodell hat. Wenn nicht, wird KI zum Beschleuniger offener Architekturprobleme.
Ein dritter Einwand lautet, dass Schnittstellen und spätere Datenbereinigung genügen würden. Genau diese Haltung führt häufig dazu, dass Inkonsistenzen dauerhaft in Nebenlogiken ausweichen. Dann steigt die technische Komplexität, während die fachliche Klarheit weiter sinkt.
Was Unternehmen jetzt praktisch tun sollten
Bevor über weitere KI-Anwendungsfälle entschieden wird, lohnt sich ein nüchterner Blick auf die operative Realität. Entscheidend sind dabei nicht zuerst Modellanbieter oder Oberflächen, sondern einige grundlegende Architekturfragen:
- Welche Geschäftsobjekte sind für spätere KI-Anwendungen fachlich kritisch?
- Welches System ist für diese Objekte und Zustände führend?
- Wo entstehen heute bereits Widersprüche, Doppelpflege oder manuelle Korrekturen?
- Welche Schnittstellen schreiben in dieselben Datenbereiche hinein?
- Wer trägt fachliche Verantwortung für Stammdaten, Prozesslogik und Änderungen?
- Welche Auswertungen oder Assistenzfunktionen wären nur dann sinnvoll, wenn diese Grundlagen zuerst geklärt sind?
Aus diesen Antworten entsteht in der Regel bereits ein realistisches Bild. Manche Unternehmen brauchen zuerst Datenbereinigung und Governance. Andere müssen Prozesszustände harmonisieren. Wieder andere müssen klären, ob ihr bestehendes ERP die führende Rolle überhaupt schon sauber ausfüllt oder ob diese Architekturfrage noch offen ist.
Wo WWInterface GmbH konkret Mehrwert schafft
Genau an diesem Punkt ist technische Nüchternheit wichtiger als Tool-Euphorie. WWInterface GmbH unterstützt nicht dabei, möglichst schnell irgendeine KI-Schicht auf bestehende Unordnung zu setzen. Der sinnvolle Beitrag liegt früher: in der Analyse von Datenstrukturen, Prozesslogik, Integrationen, Betriebsrealität und Governance-Fragen, die über die Tragfähigkeit späterer KI-Nutzung entscheiden.
Das ist besonders für Unternehmen relevant, die weder ein theoretisches Greenfield noch unbegrenzte Ressourcen haben. Sie brauchen keinen abstrakten Transformationsbegriff, sondern eine belastbare Reihenfolge: Was muss in der ERP- und Datenlogik zuerst sauber werden, damit Automatisierung, Reporting und künftige KI-Anwendungen darauf aufbauen können?
Fazit
Die Frage nach KI ist längst keine Zukunftsfolie mehr. Die entscheidendere Frage lautet inzwischen: Ist unsere operative Datenbasis dafür überhaupt tragfähig?
Wer heute sauber klärt, welche Daten fachlich führend sind, wie Prozesszustände definiert werden, wie Integrationen kontrolliert bleiben und wie Governance organisiert wird, schafft mehr als nur bessere Datenqualität. Er schafft die Grundlage dafür, dass spätere KI-Anwendungen im Unternehmen verlässlich, nachvollziehbar und wirtschaftlich sinnvoll arbeiten können.
Wenn Sie prüfen möchten, ob Ihre bestehende ERP- und Datenlandschaft bereits tragfähig für belastbare Auswertungen, Automatisierung und künftige KI-Anwendungen ist, lohnt sich vor jedem neuen Tool-Schritt eine strukturierte Bestandsaufnahme. WWInterface GmbH unterstützt Sie dabei, Datenstrukturen, Prozesslogik, Integrationen und Governance so zu analysieren, dass aus technischer Komplexität eine belastbare Entscheidungsgrundlage wird.